LLM大模型开发生态总结与应用思考
上个月参加了一场关于大模型在冶金行业应用的场景会,思考得不够深入;五一放假花了两天时间,梳理了一下目前的大模型开发生态,从开发角度理解如何利用大模型来解决行业问题。理解有限,错误难免。
大模型 #
小明在倒果汁的时候被暗杀了,因为他汁倒得太多了。
我知道的还不多。
按照目前我的理解,当前一切大模型的应用都基于LLM提供的两个能力:
- 理解力,可以概括内容、理解语意、结构化语句。
- 生成力,可以生成内容。
这两个能力也直接促进了RAG、Agent等概念的兴起,所有工具集都依赖于这两个能力。所有的应用也都是在这两个能力上扩展与想象,创造无限可能。
对应地,openai有两类主要api:
- text completion, 文本补全,一问一答,某种程度上体现了生成力。
- chat completion, 对话补全,需要记住上下文,某种程度上体现了理解力。
当然有时候这两类是融合在一起的,不好区别。实际上openai的对话上下文都是通过assistant角色带入的,结合该角色内容返回结果,总体看起来本质上也是一问一答。但这也可能产生新的问题:long context问题,也就是扔给大模型的太多,消化不良。
长上下文是大模型的一个卖点,如kimi声称可以支持200万token,可以扔进去一本红楼梦。但我已经排队2个多月了,据称kimi CEO都在出售自己股份了,我还是没体验到。
长上下文会使大模型的记忆能力下降,无法建立明确的上下文关联,造成长距离的信息,会让大模型看上去很傻。这一点脱口秀演员就做得挺好,来个call back,结尾要呼应上开场,增强听众记忆,听懂掌声。
模型的分类 #
现在比较常用的模型应该分为以下几类:
- 推理模型 inference/ reasoning, 就是我们所说的text-generation模型,大模型
- embedding模型,用以将分段后的数据集文本做嵌入时使用,或对提问做向量化等
- Rerank模型,主要在做RAG时,对检索到的候选文本(向量库中的高相关性文档)与用户提问做再排序,提高关联性。如:Cohere Rerank 模型
- 语音转文字模型,asr(automatic speech recognition)模型,如:openai的Whisper3,已开源,可自托管。
- 文本转语音模型,tts(text to speach)模型,开源的很多,如:vits等
- 其他生图生视频等多模态模型,生态复杂,暂且不表。
我们所说的大模型一般是指推理模型,也是大部分应用的基座。基于推理模型结合其他开源模型,世面上已经出现了丰富的富有想象力的应用。
部署方式 #
LLM的两种部署方式:
- 使用商业模型的api作为基座,融入到业务中。对于工业应用,这一点基本是不能接受的,因为数据安全问题。
- 使用训练好的开源模型运行起来。
对于程序员来说,未来的方向是私有化部署,部署方式则是从model托管平台拉取对应的模型数据,然后启动。并使用RAG或者微调技术,对开源的模型进行个性化训练。了解开源社区及周边的开发生态,是一般开发者的关注重点。
托管平台 #
抱抱脸(https://huggingface.co ) 是一个大模型(Models)和数据集(Datasets)托管平台,平台提供了大量开源社区的模型,也有开发者微调后上传的模型。比如llama3-8b的中文支持不够好,就有开发者加入中文语料微调后上传。我们就可以直接使用微调后的中文大模型,如: https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat-GGUF-8bit
) 是一个大模型(Models)和数据集(Datasets)托管平台,平台提供了大量开源社区的模型,也有开发者微调后上传的模型。比如llama3-8b的中文支持不够好,就有开发者加入中文语料微调后上传。我们就可以直接使用微调后的中文大模型,如: https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat-GGUF-8bit
该模型名中的8bit是指采用了8位的量化,减小了模型体积,提高运行速度(内存到CPU的数据传输量减小),但有一定的精度损失。
GGUF代表GPT-Generated Unified Format,是用于存储大型模型预训练结果的一种格式。它被设计为一种紧凑的二进制编码格式,优化了数据结构和内存映射技术,提供了高效的数据存储和访问方式。
另外托管平台也直接运行了对应的大模型实例,可以在平台上直接使用,如: https://huggingface.co/spaces/llamafactory/Llama3-8B-Chinese-Chat。 也可以申请抱抱脸的api key,直接调用对应的大模型。
https://groq.com 也是一个托管平台,运行了llama3、mixtrial等大模型实例。groq以速度快著称,我在vscode里安装了codegpt插件,并使用groq的provider和llama3模型,飞一般的响应速度。
类似的托管平台还有很多,如 together.ai 等。都各有特色。
本地托管 #
本地部署使用OLLAMA比较简单。安装地址: https://ollama.com/download , 安装llama3模型则使用:
ollama run llama3上述命令会在ollama平台下载最新的llama3 8b模型,并启动。启动后就在本地运行了一个私有的大模型基座,可以接收api调用了。
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"Why is the sky blue?"
}'一般的大模型的变体有两种:
- pre-trained: 预训练的,基本模型
- instruct: 指令集的,微调后支持会话的。
如果要托管一个huggingface上的微调模型,则需要先下载模型,通过以下方式:
ollama create Llama3-8B-Chinese-Chat-ARIM -f Modelfile
FROM /path/to/Llama3-8B-Chinese-Chat-GGUF-8bit.gguf
ollama run Llama3-8B-Chinese-Chat-ARIM
FROM llama3
PARAMETER temperature 1
SYSTEM """
You are Mario from super mario bros, acting as an assistant.
"""我的MacBook Pro M1 8G,勉强能运行,CPU和内存都飚满。
本地大模型UI #
ollama提供了命令行,可以直接调用本地托管的大模型,但是终归不是那么方便的,如果能实现类似chatgpt的UI就好了,故就有了 openwebUI。https://openwebui.com/
openwebUI 可以docker启动,实现了部署一个大模型使用的UI界面,类似chatgpt的对话窗口。它的增强能力体现在:
它可以同时支持不同的大模型,在对话窗口随意切换。
提供在本地实现RAG过程,直接添加文本
嵌入文档功能
管理大模型,如下载、删除等
它跟ollama的生态是配套的,可直接使用docker启动:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main大模型代理 #
大模型是一切应用的基座,大模型种类繁多,每天都有新的模型诞生,但对于应用来说,依赖大模型的能力却始终没变,故可以使用代理服务实现大模型基座的一致性,而不用关心每个大模型的调用细节。
大模型代理可以使用: https://docs.litellm.ai/docs/ , litellm是个代理模型,代理后提供统一的调用api接口的方式,不用关心背后使用的大模型基座运行在哪里。如:
from litellm import completion
import os
os.environ["HUGGINGFACE_API_KEY"] = "huggingface_api_key"
# e.g. Call 'WizardLM/WizardCoder-Python-34B-V1.0' hosted on HF Inference endpoints
response = completion(
model="huggingface/WizardLM/WizardCoder-Python-34B-V1.0",
messages=[{ "content": "Hello, how are you?","role": "user"}],
api_base="https://my-endpoint.huggingface.cloud"
)
print(response)它的代理config.yml格式如下:
model_list:
- model_name: gpt-3.5-turbo # user-facing model alias
litellm_params: # all params accepted by litellm.completion() - https://docs.litellm.ai/docs/completion/input
model: azure/<your-deployment-name>
api_base: <your-azure-api-endpoint>
api_key: <your-azure-api-key>
- model_name: gpt-3.5-turbo
litellm_params:
model: azure/gpt-turbo-small-ca
api_base: https://my-endpoint-canada-berri992.openai.azure.com/
api_key: <your-azure-api-key>
- model_name: vllm-model
litellm_params:
model: openai/<your-model-name>
api_base: <your-api-base> # e.g. http://0.0.0.0:3000运行即可:
litellm --config your_config.yamllitellm提供了统一的调用api,支持100+的大模型基座,非常适合同时使用多个大模型基座的情况。
定制化 #
事实上,当一个开源的base model发布后,开源社区会积极地进行微调和量化,以适应特殊任务、减小体积和资源依赖。然而有时候光有社区的微调是不够的,还需要针对自己的行业和场景重新定制化。对于大模型的定制化,主要有两种方式:fine tuning 和 RAG。
fine tuning #
ft的难度和需要的资源较高,一般不使用该方法实现定制化。在openai的文档中,可以使用api的方式实现对chatgpt-3.5-1220等预训练模型的ft,方法较为简单,也不需要耗费资源,但需要消耗token,微调过程有可能是十几分钟,也可能是几天。微调后相当于得到预训练模型的分叉模型,实现定制化。但无论使用哪种方法,ft的过程一般分为以下几步:
- 准备数据集:该数据集应该包含你的任务所需的示例,并且已经被预处理成模型可以处理的格式。
- 加载预训练模型:加载一个适合你任务的预训练模型。Hugging Face提供了大量的预训练模型和相应的tokenizer。
- 定义训练参数:设置训练过程中的参数,如学习率、训练轮数(epochs)、批次大小(batch size)等。
- 定义优化器和损失函数:选择合适的优化器(如AdamW)和损失函数(如CrossEntropyLoss)。
- 训练模型:使用你的数据集对模型进行fine-tuning。
- 保存和评估模型:训练完成后,保存模型并使用验证集或测试集对其进行评估。
以下是使用Hugging Face的Transformers库和PyTorch进行fine-tuning的简化代码示例:
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
from torch.utils.data import DataLoader
import torch
# 准备数据集
# 假设我们有一个自定义的Dataset类
from my_dataset import MyDataset
train_dataset = MyDataset(...) # 实例化训练数据集
val_dataset = MyDataset(...) # 实例化验证数据集
# 加载预训练模型和tokenizer
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 将数据集转换为tokenizer的输出格式
train_dataset = tokenizer(train_dataset, padding=True, truncation=True)
val_dataset = tokenizer(val_dataset, padding=True, truncation=True)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
)
# 创建Trainer对象
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
# 训练模型
trainer.train()
# 保存模型
model.save_pretrained("./saved_model")
# 评估模型
eval_results = trainer.evaluate()
print(eval_results)这个过程需要消耗大量资源,我的mac恐怕是支持不住,没有演练过。
RAG #
RAG就是检索增强生成,是比较常用的导入知识的一种方法。将自己的知识库向量化到数据库中,主要分为4个过程:
- load,如pdf文件、csv文件等,这里就是我们自己的知识库文件,如冶金流程工程学。
- split:分割文档,以便向量化
- embedding:使用bert等模型对文档向量化
- store:存储到向量数据库
- retrieve: 根据输入文本,向量化后到数据库中寻找最相似的文档并返回
- query: 将检索到的文档作为上下文以及原问题发送给大模型,返回答案

主要的问题:
- split的太大,同一文档中非相关的内容就越多,生成模型就可能出现无关或错误的信息,导致答案不准确。
- split的太小,文档块太小,得到的信息太细节,但是忽略该细节的上下文中重要的信息,也会导致答案不准确。
解决方法:窗口上下文检索, https://waytoagi.feishu.cn/wiki/PWpWwi7KPihhoCkEJK0ctD3Annd
另外根据langchain框架,可以使用以下方式实现这一过程:
from langchain.document_loaders import TextLoader
# 加载数据
loader = TextLoader('your_data.txt')
documents = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
from langchain.embeddings import HuggingFaceEmbeddings
# 初始化嵌入模型
embedding_model = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2')
# 生成嵌入
embeddings = [embedding_model.embed_text(text.page_content) for text in texts]
from langchain.vectorstores import Pinecone
# 假设使用Pinecone作为向量数据库
import pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
index_name = "my-embeddings-index"
# 存储嵌入
vectorstore = Pinecone.from_documents(texts, embedding_model, index_name=index_name)
query = "你的查询文本"
docs = vectorstore.similarity_search(query, k=5)
for doc in docs:
print(f"相关文档: {doc.page_content}")RAG一般指的是最后一步 retrieve。模型在生成响应之前会先查询一个知识库(如文档库、语料库等),检索与输入查询最相关的片段,然后利用这些片段来生成最终的输出。
def generate_response(self, query):
# 步骤1:检索相关信息
related_docs = self.retriever.retrieve(query)
# 步骤2:准备输入给生成模型的数据
context = " ".join([doc.content for doc in related_docs])
# 步骤3:利用检索到的上下文生成最终响应
response = self.generator.generate(context + " " + query)
return response由上可以看到,辛苦嵌入的知识库,只被用作context加强了提示词的语意,其他过程跟普通的直接使用大模型并无差异。
当然在retrieve环节有很多细节调整,langchain有很多retriever,实现了不同机制下的检索增强,这些机制非常重要。因为大模型用好的关键是写好提示词,充分利用知识库的知识,把提示词写好,是retriever的重要职责之一,常用的retriever有:
- Vector Store Retriever:这种最简单,直接从向量库里找关联性最高的文档作为上下文
- MultiQueryRetriever:先用大模型对查询文本来个多方位的意译,分别取意译的高相关文档,然后交叉联合,以此作为上下文。
- Self-Query Retriever:先使用大型语言模型(LLM)从用户的原始问题中结构化查询条件,然后从向量数据库中过滤元数据的信息。该模式可以获取精确的结构化信息,提升语意。
- ContextualCompressionRetriever:在检索到相关的文档块后,使用压缩算法(如 LLM)来仅提取与用户问题相关的内容,从而提高检索质量并减少资源浪费。
- SVMRetriever 和 TFIDFRetriever:这两种检索器分别基于支持向量机(SVM)和词频-逆文档频率(TF-IDF)算法来检索文档。SVMRetriever 通过学习文档的特征来区分不同类别的文档,而 TFIDFRetriever 则根据词项在文档中的出现频率和在整个文档集合中的罕见程度来评估词项的重要性。
检索器非常多,可以根据业务需求调整检索器,以便获得更好的上下文,提高查询质量。
工具化 #
基本概念 #
在大模型出现之前,有个叫RPA的东西。RPA就是Robotic Process Automation, 它的主要能力就是手动配置好工作流,启动后按照预设的流程执行动作。比如执行报销流程的机器人,输入可能是一张发票图片,输出可能是账户上报销到的费用。中间过程涉及图像识别、表单填写、签字、对账、汇款、结算等多个环节。但这些环节都是人为预先设计好的,RPA只要按照预先设计好的流程走一遍即可,这就实现了自动化的过程。
RPA曾经在2015年后风起云涌,融资无数。但2020年以后爆冷,资本开始缺乏信心,RPA走低。其中主要原因是无耐心资本,SaaS不太适合中国企业,同时RPA技术本身有硬伤。
但现在有点不同了。
AI的出现让RPA有了大脑,人工配置流程的过程,现在都可以交给大模型了。但方法论本身并没有发生变化。工具化层面包括以下概念:
- tools: 工具,即每个步骤可以使用的工具,内部调用或者外部api 调用等等,都属于工具的范畴,它构成了工作流程的一个功能节点。
- chain/workflow: 可以理解为工作流,是一个支持条件的DAG(有向无环图),它的节点Node可以是一个tool。
- agent:代理或智能体,这是区别普通工作流中最大的不同,是大模型应用中最具特色的一部分。
这里的重点说说agent。它是大模型应用下的重点。agent下可以访问单一tool,并根据用户输入确定要使用的工具。它可以使用多个工具,并使用一个工具的输出作为下一个工具的输入。简而言之,利用大模型的能力,agent实现了自己决定如何创建一个工作流来实现任务。主要有两种类型的代理:
- Plan-and-Execute Agents 用于制定动作计划
- Action Agents 决定实施何种动作
调用过程如下:
def test_conversation_agent():
search = GoogleSearchAPIWrapper()
tools = [
Tool(
name = "Current Search",
func=search.run,
description="useful for when you need to answer questions about current events or the current state of the world"
),
]
memory = ConversationBufferMemory(memory_key="chat_history")
llm=OpenAI(temperature=0)
agent_chain = initialize_agent(tools, llm, agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=True, memory=memory)
print(agent_chain.run(input="用中文回答中国人口数量"))它的执行过程如下:
> Entering new chain...
Thought: Do I need to use a tool? Yes
Action: Current Search
Action Input: 中国人口数量
Observation: 中华人民共和国成立时,中国大陆人口约5.4亿,占世界人口的22%。和许多发展中国家一样,从1950年起,由于社会较为稳定,死亡率下降,预期寿命逐渐延长,人口因此迅速增长 ... May 11, 2021 ... 十年一次的普查显示,以2020年11月1日为标准时间点,中国总人口为14亿1178万人。此前英国《金融时报》援引知情人士称中国总人口已低于14亿人,出现了“自 ... 中国是一个以汉族为主多民族国家,汉族目前占总人口的91%,其余为少数民族,及极少数的归化外国移民。据中华人民共和国国家统计局于2020年1月17日发布数据,
Thought: Do I need to use a tool? No
AI: 根据中国国家统计局的数据,截至2020年11月1日,中国总人口为14亿1178万人。此外,中国汉族人口占总人口的91%,其余为少数民族,及极少数的归化外国移民。
> Finished chain.
根据中国国家统计局的数据,截至2020年11月1日,中国总人口为14亿1178万人。此外,中国汉族人口占总人口的91%,其余为少数民族,及极少数的归化外国移民。由上就实现了一个根据搜索引擎结果,回答问题的大模型,并且它还有记忆。认真观察,agent自己在思考和决策,像一个大脑在工作。
通用人工智能(AGI)将是AI的终极形态,几乎已成为业界共识。类比之,构建智能体(Agent)则是AI工程应用当下的“终极形态”。可以看到Agent的思考能力是促成工作流创建的根本,这里有很多Agent的类型,具体不在详述,可结合langchain的文档理解。https://python.langchain.com/docs/modules/agents/concepts/, 总之它的原理可以如下表达:
next_action = agent.get_action(...)
while next_action != AgentFinish:
observation = run(next_action)
next_action = agent.get_action(..., next_action, observation)
return next_action工具生态 #
目前已有很多创业项目实现了类似工作流或者智能体的应用,如字节的coze(https://coze.com) 和近期热门的 dify (https://dify.ai). 他们都实现了类似工作流的应用,即通过拖拽的方式加入不同节点,然后建立连线关系,配置一个工作流。总体感觉跟RPA非常类似,但有一点非常不同,即它的很多工具节点都有语意理解能力,实现了结构化数据,配合外部系统的api调用等,实现了更多功能。
知识库
知识库可以丰富语意,基本的方法论也是使用嵌入技术让大模型更懂自己的专业术语,从而更好地应用工具,实现agent工作流。几乎所有的平台应用都实现了知识库模块。基本的过程是:导入csv或pdf文件,嵌入,使用。
插件/工具
coze下插件对应dify下供应商Provider的概念。都可以自己创建一个供应商以及供应商下的多个工具。创建完后随时可以使用。
记忆
上下文的记忆功能。
还有很多其他的应用,大体上都是类似,保持一致的方法论。
应用到工业上 #
大模型的来临,无论从新生的应用还是日常使用的来看,依然在拿着它的两个能力在扩展,即:理解力和生成力。既然是在理解,那么理解就会有偏差。在工业领域,我们做的系统都是决策系统,决策系统对当前状态的理解是精确的、结构化的,不允许有偏差,微弱的偏差可能会造成决策结果的巨大差异,所以直接让LLM参与到决策系统是不大现实的。
但依然有使用LLM的空间。
规则引擎 #
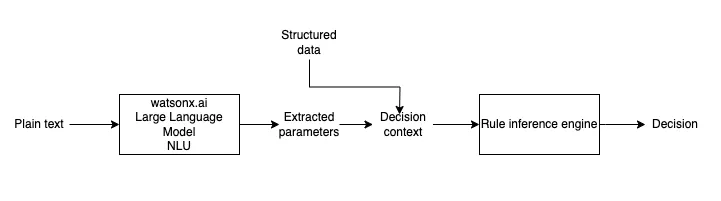
规则引擎在我们目前的系统中使用较为频繁。系统将事实facts传入到规则集ruleset中,规则引擎返回对应的决策结果results,完成一次调用。在这个过程中,有几个可以使用大模型的切入点:
- 规则集的结构化: ruleset本身是语义化的,我们拿到现场的规则通常是一个pdf文件,里面有大量的规则表和文字描述。在一般的方法中,我们只能通过逐个解读、理解,然后将它结构化并存储下来,以便下次直接调用。这个过程通常是繁琐的过程,这时候LLM就可以发挥它的作用,通过建立上下文提示词,对规则集进行进行结构化表达,并建议评估工具实现对规则集的验证,防止语意理解出错。即便是理解出错,我们依然有纠正的机会,将规则集纠正为正确的描述。
- 事实的结构化:在大多数时候,我们调用规则引擎时传入的事实facts是精确的和结构化的,但如果是会话系统,LLM则会在事实结构化方面大放光彩,如:SPHC钢种在CC1连铸机上的拉速应该设为多少? 该语句表达了多个信息:钢种:SPHC,设备:CC1, 工序:CC,当前时间:夏季,期望的调用的规则集:拉速规则表。此时可以利用LLM的理解力,将用户的询问结构化,结构化后的数据传入到规则引擎调用,并返回结果results。这里就需要开发对应的agent和对应的tools实现上述功能。通常情况下,会话系统是不直接参与决策的,故能直接反馈给用户信息,没有安全问题。
- 规则集选择问题:因为规则集选择在差异上很大,语意上通常处于长距离,故能使用LLM的理解选择规则集,如上文的拉速规则集,当用户询问拉速时,故能选择到拉速规则集。
- 决策结果的语义化:规则引擎提供的决策结果通常是精确的,如上文的拉速,返回结果可能是 1.3~2.9或者没有命中。当实际中,我们可能需要给用户提供更多信息。如:SPHC钢种在CC1连铸机上的拉速其实与CC1设备无关,但它跟铸坯的宽度有关,当宽度大于2000时,为1.3~2.9;当宽度小于2000mm时为1.5~2.8。 通过将精确的决策结果或者异常(没提供铸坯宽度信息),表达为语义化的决策结果,通常比干巴巴的数字含有的信息量更大和更优化。当然这里仅限于chat环境,如果规则引擎的调用处于决策系统的关键一步,还是希望得到精确的决策结果。
这个想法在一篇博客中得到验证,https://medium.com/@pierrefeillet/approaches-in-using-generative-ai-for-business-automation-the-path-to-comprehensive-decision-3dd91c57e38f 。 该文也是探讨了LLM模型的功能切入点应该放置在何处合适,也讨论了可靠性(精确性)和适应性的矛盾。
表面质量缺陷检测 #
基于图像表面质量检测的CV技术应该已经很成熟,比如传统的CV和深度学习CNN或GAN等,这里结合LLM探讨一种方法论。我们知道在RAG过程中,实际上图片也可以实现向量化,那么可以按照这个方法论,实现图片信息和文本信息映射到同一个空间。
CLIP(Contrastive Language-Image Pre-training)是一个由OpenAI开发的多模态模型,它能够将图像和文本映射到同一个向量空间。CLIP模型通过训练图像和文本描述之间的对比性,使得相关联的图像和文本在向量空间中更接近。CLIP模型的主要用途之一是实现图像和文本之间的语义关联。给定一张图片,CLIP可以:
- 返回图像特征向量:这是一个高维空间中的点,可以用于比较不同图像的视觉内容,或者与文本描述进行匹配。
- 图像-文本对比学习:使用图像特征向量,CLIP可以执行零样本(zero-shot)分类任务。这意味着,即使没有对特定类别的显式训练,CLIP也可以根据提供的文本描述识别图像中的对象或场景。但不一定,这里可能是个坑,场景差异小的话是否能够识别?
- 基于文本的图像检索:如果有一个图像数据库和相应的文本描述,CLIP可以用来检索与给定文本描述最匹配的图像。
- 生成图像的文本描述:虽然CLIP本身不直接生成文本描述,但可以使用图像特征向量来搜索与训练数据集中的文本描述最接近的向量,从而找到图像的潜在描述。
- 评估图像与文本的匹配度:CLIP可以计算图像特征向量和文本描述向量之间的相似度,通常使用余弦相似度。
试想如果我们使用了有缺陷的图片和对应的缺陷描述、可能产生的原因、处置方式等文本信息训练了模型,那么我们可以实现:
- 给定一张图片,利用上述5, 可以实现对图片的文本描述,以达到识别图片中出现的表面缺陷,并能结合不同场景表达缺陷出现的原因和处置方式,甚至判级别。
- 利用上述3,可以检索到历史图片。
- 利用LLM,可以对映射到相同空间的文本进行语义化总结,概述。
另外,结合RAG过程,使用向量化数据库简化上述操作,实现简化模型部署,开发框架更加明确一致。
这个应用只是我的想象,没有实践过,不一定可行,特定是因为表面缺陷的场景差异非常小,识别比较困难,特征提取可能是个大问题。
最优化问题的应用 #
我们目前所做的系统都是决策系统,最后都可以归纳为一个最优化问题。但因为约束比较多,解空间比较大,一般不可能直接使用最优化解法,而是使用一些启发式算法来解决,如蚁群算法、遗传算法等。这些算法都需要精确的表达,没有LLM太多的发挥余地。我认为,如果可能得话,有以下几个注入点:
- 建模方面:作为工具帮助业务人员更好地理解条件和目标,建立对应的模型;
- 调参方面:借助LLM对参数给与提示。
- 算法解释:似乎还没有良好的结合点,有些算法是可以解释的,需要针对具体的情况,还不能作为一个方法论。
会话模式下的应用 #
会话模式其实很好理解,把它作为一个专家chat系统,并增加钢铁领域的一些知识,就可以炼出不同的冶金专家。如:
- 材料专家: 微调或者RAG方式实现,导入材料数据,实现:材料数据查询、用材指导、牌号对照等功能。
- 工艺专家:同上导入工艺数据,实现工艺指导。
在这方面大模型有一个MoE的概念,大体的意思是现在预训练的大模型比较稀疏,也就是当接收输入时,只有少量的神经元被激活,大部分的神经元无动于衷。这就导致很多无用的计算。于是就出现了MoE的大模型,如:mixtral 8*7B, 这里的8就是8个专家子模型。后来又进化出DeepSeek模式,即超专家和共享专家。这里浅显地理解如下:
- 不需要全才,只需要专才。专才只需要对自己擅长的领域应激,越学习越聪明。
- 全才会让自己变笨。试想一个专家即是唯心主义者又是唯物主义者,接收到的外部刺激,会让它即唯物又唯心,聪明得笨死了。
- 只让专才回答它擅长的领域,别的专家就别掺和了。
及早打造企业的MaaS平台 #
私有化的MaaS平台一定是未来的趋势,能实现诸多定制化的应用。如知识库、大模型基座的选取、工具集的定制化等。目前也有很多开源的可用,未来的生态也会越来越丰富。及早的构建私有化MaaS平台,可以积累经验,同时融合目前的产品,对产品进行增值。
一点总结 #
通过以上的思考,逐渐认识到LLM与实际问题,在两个方面存在矛盾:
- 精确性:结构化的数据、精确的数据
- 实时性:没有修改和确认的机会
大模型可理解很多语意,但无法实现精确性。于是我得出结论:
凡是需要精确且实时的系统,都无法直接使用LLM。
只有在不精确和离线环节下,大模型才有用武之地。
LLM的应用未来 #
AI BOT及工作流 #
AI的应用平台也越来越多,有的称自己AI BOT,有的称自己为 LLMOps,作为平台其实要回答一个问题,你的用户到底是谁:
- 普通用户: 我认为不太行,因为使用门槛过高。到Gpts这个级别已经是极限,也还需要很长的培育过程;
- 企业用户:可行,但又是SaaS应用,最大的问题是数据安全问题,除非私有化部署。这是一个方向,dify似乎是往这个方向走。逐步实现MaaS平台。
- 开发者: 不太可行。开发者的确有能力创建各个BOT,但只靠兴趣的话无法实现差异化。拖拽很简单,但简单的东西就无法产生价值。这一块我觉得开发对应的tools可能是一个切入点。
一般企业最后可能都会有一个MaaS平台,在这个平台上实现知识库、BOT等,是一个不错的切入点。而且MaaS本身也可以作为开发平台,结合自身行业的特点产生更多的附加值。目前开源的居多,可以搭建一个。
AI问答引擎 #
- AI 搜索引擎的第一要义是准确度。
准确度的决定性因素主要是两个:问答底座模型的智能程度 + 挂载上下文的信息密度。做好 AI 搜索引擎的关键,选用最智能的问答底座模型,再对 RAG 的检索结果进行排序去重,保证信息密度。第一个步骤容易,第二个步骤很难。所以现在市面上大部分的 AI 搜索引擎,包括 Perplexity,准确度也就 60% 左右。
- ChatGPT自己做搜索,首先保证了问答底座模型的智能程度。
其次在检索联网信息层面会做黑盒优化,包括 Query Rewrite / Intent Detection / Reranking 这些措施。 最终依赖自身模型的 Long Context 特性,效果就能做到比其他纯 Wrapper 类型的 AI Search Engine 要好一点。
- 我并不觉得大模型厂商自己做 AI 搜索 就一定会比第三方做的好。
底层对 RAG 挂载上下文内容的优化,ChatGPT 能做,第三方也可以做。
- 做好 AI 搜索引擎,最重要的三点是准 / 快 / 稳,即回复结果要准,响应速度要快,服务稳定性要高。
其次要做差异化创新,错位竞争。比如对问答结果以 outline / timeline 等形式输出,支持多模态搜索问答,允许挂载自定义信息源等策略。
- AI 搜索引擎是一个持续雕花的过程。
特别是在提升准确度这个问题上,就有很多事情可以做,比如 Prompt Engineering / Query Rewrite/ Intent Detection / Reranking 等等,每个步骤都有不少坑。其中用 function calling 去做 Intent Detection 就会遇到识别准确度很低的问题。用 llamaindex + embedding + Vector DB 做 Reranking 也会遇到排序效率低下的问题。
- AI Search + Agents + Workflows 是趋势。
AI Search 做通用场景,通过 Agents 做垂直场景,支持个性化搜索需求。通过 Workflows 实现更加复杂的流程编排,有机会把某类需求解决的更好。使用 GPTs 做出的提示词应用或知识库挂载型应用,价值点还是太薄。
- 我个人不是太看好垂直搜索引擎。
一定程度上,垂直搜索引擎可以在某个场景做深做透,但是用户的搜索需求是非常多样的,我不太可能为了搜代码问题给 A 产品付费,再为了搜旅游攻略给 B 产品付费。垂直搜索引擎自建 index 索引,工程投入比较大,效果不一定比接 Google API 要好,而且接入的信息源太有限。
- AI 搜索是一个巨大的市场,短时间内很难形成垄断。
海外 Perplexity 一家独大,国内 Kimi/秘塔小范围出圈。各家的产品体验,市场占有率还没有达到绝对的领先,后来者依然有机会。
最后,我所说的都是错的。